


The XML Connection: How docx and odt Share Common Ground

Microsoft Word is one of the most popular and widely used word processors in the world. It allows us to create, edit, and share documents for various purposes, such as writing letters, reports, essays, resumes, and more. By extension, the docx format is one of the most common extensions someone will see in their lifetimes. It’s even more ubiquitous than Microsoft Word itself as it’s a supported export for the most commonly used word processors like Google Docs and LibreOffice. But for such a ubiquitous file extension how does it actually work? Let’s begin with a simple Microsoft Word Document.
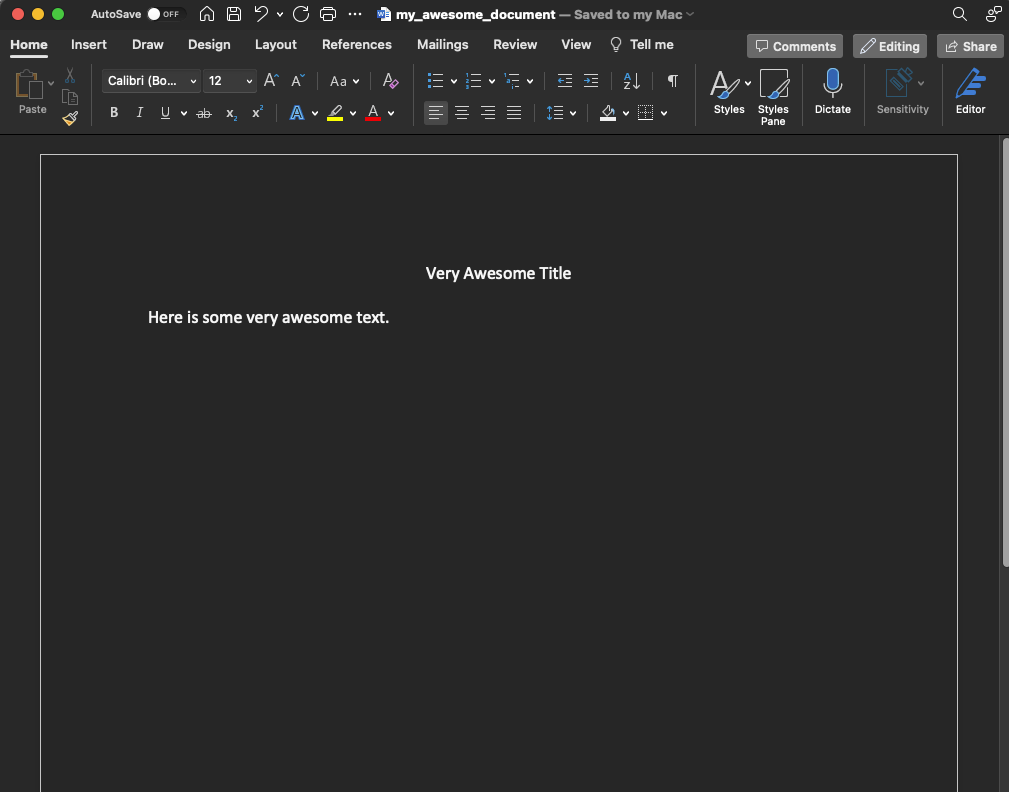
Saving it to my Macbook I can actually open up the file using my text editor Emacs. You may or may not be surprised to see that it’s actually a collection of xml files.

A typical DOCX file contains the following parts:
[Content_Types].xml: Defines the types of files contained in the package, such as XML files or images
_rels: Folder containing relationship files that link the different parts of the package together
docProps: Folder containing property files that store metadata about the document, such as title, author, keywords, etc
word: Folder containing the main files that define the content and structure of the document
document.xml: File containing the main body of the document in XML format
styles.xml: File containing the styles used in the document, such as fonts, colors, margins, etc
numbering.xml: File containing the numbering schemes used in the document, such as bullets or outlines
settings.xml: File containing the settings applied to the document, such as language or compatibility options
theme.xml: File containing the theme applied to the document, which defines its overall look and feel
fontTable.xml: File containing the fonts used in the document
webSettings.xml: File containing the settings for web viewing of the document
media: Folder contains any media files embedded in the document, such as images or sounds
By examining the document.xml file, we can see the actual text typed into our document.
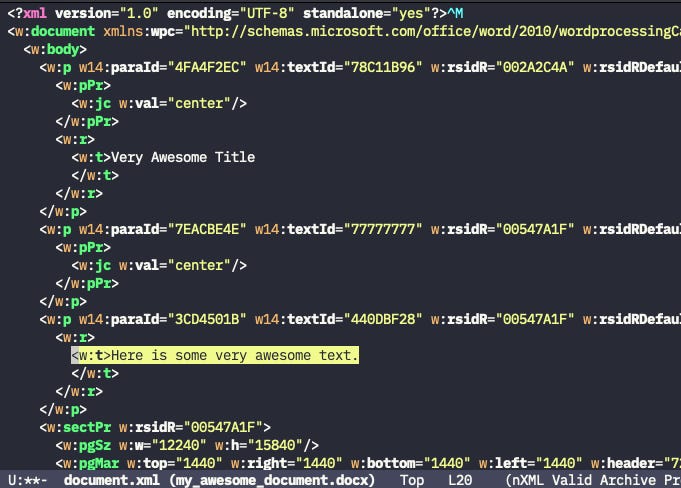
The title, for example, has the value <w:jc w:val="center"/> associated with it because I aligned the text to the center. Conversely, the "Here is some very awesome text" doesn't have such alignment, as it is left aligned by default.
You might be curious about the advantages of using multiple xml files over a single binary file. In the past, Microsoft's file format for Word documents was a single binary file (doc), which, despite its simplicity, had the disadvantage of being more susceptible to file corruption. If the file became corrupted, it was considerably more challenging to recover the data from the binary format. However, with the introduction of multiple xml files, primarily focused on styling, the file format became more resilient against corruption.
To illustrate this point, let's consider what a minimal docx file would look like. Creating such a file is surprisingly straightforward. It only requires two folders and three files.
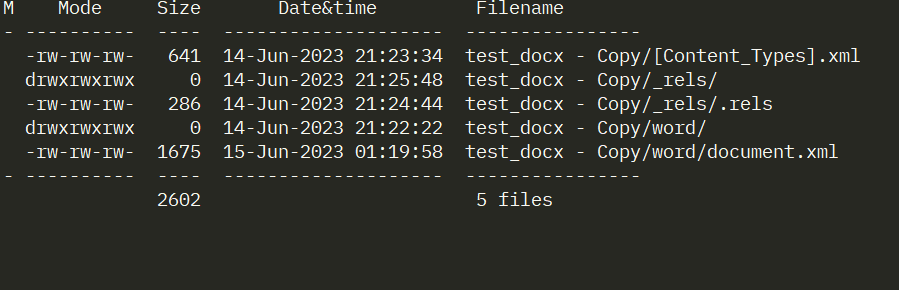
Here are the steps required to create the file above…
Change the extension from docx to zip
Unzip the file using your favorite program
Delete everything but the files shown in the screenshot above
Delete the lines in the
[Content_Types].xmlfile and the_rels/.relsfile that reference the files you deletedZip it up again and give it a docx extension and it will be read by your favorite word processor with no problems
As you can see the document doesn't actually require all the other files to display the text. It will resort to default styling when no other styling information is present in the file. And if all else fails, as long as you have the word/document.xml file, you can always extract the text between the <:t w> tags which would allow you to recover a corrupted docx file where everything but the content.xml file was corrupted. The text you get won’t be pretty, but for a file format that is ultimately about storing text, being able to recover as much of the original text as possible seems like a good trade off to me.
It's worth noting that the docx format is an open standard governed by the Ecma International standards committee as Office Open XML. When this standard was accepted, around 2008, Microsoft further supported the openness of the docx file format by including it in their Microsoft Open Specification Promise which says…
Microsoft irrevocably promises not to assert any Microsoft Necessary Claims against you for making, using, selling, offering for sale, importing or distributing any implementation to the extent it conforms to a Covered Specification
This explains why software like Google Docs and LibreOffice are able to support the file format. This has not been without controversy though, as docx was accepted by the ECMA International standards committee after the ODT format had already been accepted a few years earlier and standardized as the international format. Some accused Microsoft of using its considerable influence to get their file format standardized as well, to stave off competition. And while docx is an open standard, as one internet user points out…
Microsoft will never promise to not include new, proprietary, pieces to one previously open standard.
Which harkens back to Microsoft’s late 90s to early 2000s Embrace, Extend, Extinguish philosophy. So, if we don’t want to use docx what else is there?
How about ODT?
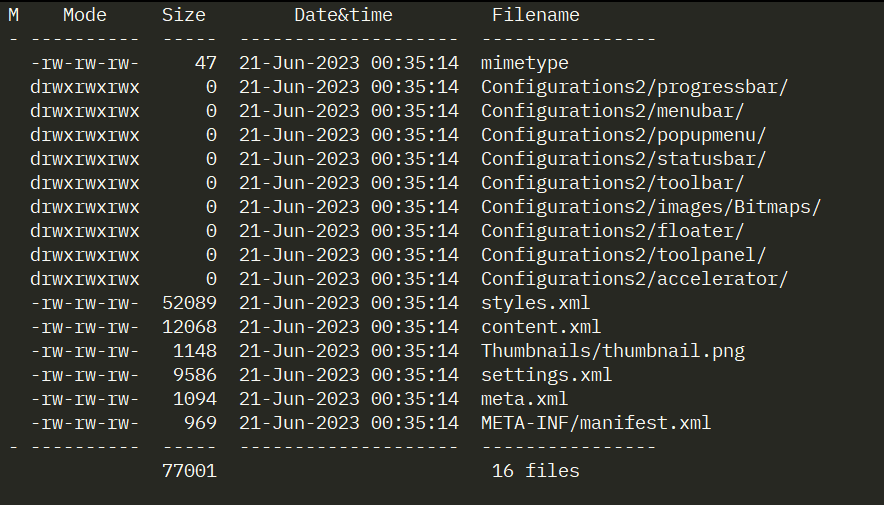
For those of you worried about Microsoft’s dominance in all things computing, or who prefer to use Word Processors other than Microsoft Word, Open Document Text (odt) is another file format that encodes word processing documents. The structure of odt files is similar to docx, consisting of multiple XML files alongside additional data. Below is an unzipped example odt file that has the same text saved in it, that we previously saw in the docx file.

There are 17 files inside of the odt which can be broken down into these categories
mimetype: Defines the type of the archive. For an ODT file, it would contain the text "application/vnd.oasis.opendocument.text"
META-INF/manifest.xml: This XML file provides a list of all the files in the archive, along with their types. It is used to inform the software reading the document what files to expect and what they represent
Configurations2: This is actually a folder that contains configuration settings and other associated files for the document. This can include accelerator configuration settings and images used by the document
Pictures: This folder includes any images or other media that are embedded in the document. Each media file is saved separately within this folder
content.xml: This is the main file of the document, containing the actual text content of the document, formatted using XML tags. It includes all of the paragraphs, headings, lists, tables, and so on, each marked up with XML
styles.xml: This file defines the styles used in the document. This can include paragraph styles, character styles, and page layout styles, among others
meta.xml: This file contains metadata about the document, such as the author, creation date, modification date, and so on
settings.xml: This file contains various settings for the document, such as whether to show the grid, what language to use for spell checking, and so on.
Thumbnails/thumbnail.png: This folder contains a thumbnail image of the first page of the document. This is what you see in your file manager before you open the document
manifest.rdf: This is an optional file that can be used to store metadata about the document in the Resource Description Framework (RDF) format. RDF is a standard model for data interchange on the Web, and it provides interoperability between applications that exchange machine-understandable information
Similar to the minimal docx file, not all of these files are required to make up a minimum viable odt. Like before, we can rename an odt to a zip file, open it up and delete all extra data inside of it.

This time we are just left with 3 files, content.xml, META-INF/manifest.xml, and mimetype. Again, we must delete the references to the deleted files in the remaining xml files but that just requires removing a few lines from each of them. What we are left with is an odt that will have the bare minimum styling required to display the text.
An advantage of using XML files to encode file formats is the flexibility it offers. XML can not only be used to encode odt files but can encompass your entire office suite. The Open Document specification supports various file extensions, such as…
.odt for word processing (text) documents
.ods for spreadsheets
.odp for presentations
.odg for graphics
.odf for formulas and mathematical equations
If we were to open up a LibreOffice Impress (LibreOffice’s version of PowerPoint) file saved as an odp we see that it contains the exact same type of files as the odt.
And if you open up content.xml, you’ll see a familiar structure with text in between text tags.

Now, let's consider how we determine the proper way to render the XML when the format is the same across different applications. The key lies in the mimetype file. In our odp file, the mimetype file specifies the following:
Application: application/vnd.oasis.opendocument.presentation
In our odt file the mimetype looks like this
application/vnd.oasis.opendocument.text
Using the mimetype file you can instructs the program to interpret the data differently while using the same file structure. This simplifies parsing across the different filetypes greatly, making it easy to parse any of the other files in the office suite if you already know how to parse one. I think that’s pretty cool and I hope you do too!
Call To Action 📣
If you made it this far thanks for reading! If you are new welcome! I like to talk about technology, niche programming languages, AI, and low-level coding. I’ve recently started a Twitter and would love for you to check it out. I also have a Mastodon if that is more your jam. If you liked the article, consider liking and subscribing. And if you haven’t why not check out another article of mine! Thank you for your valuable time.
OpenOffice: The Zombie Software That Won’t Die

Apache Open Office has not had a major release in over 9 years, yet it is still one of the most popular free and open source implementations of an office suite. In fact, just last year it celebrated more than 333,333,333 downloads.
Really interesting. Thanks! Kind of blew my mind, I have to admit, how these file formats work under the hood.